
Happy New Year everyone! Here at ONEsite, we constantly strive to increase performance and optimize our client and end users’ experience. Last summer, we targeted the message center as a key system which could use optimization. The Message Center is employed by users as a private messaging system; it is also used by network administrators as a key way to communicate with their users, either through our control panel interfaces or our APIs. As such, the Message Center is both a popular user feature and one that must scale to millions of message recipients for one message.
One of the major architectural pieces of our platform that contributes to our scalability is our functional partitioning of key systems and logical sharding onto isolated highly available (HA) database clusters. When developing new systems isolating backend storage is trivial – just define a pool and start storing data. However, as was the case with the message center, migrating data from one cluster to a new cluster without having downtime can be rather tricky.
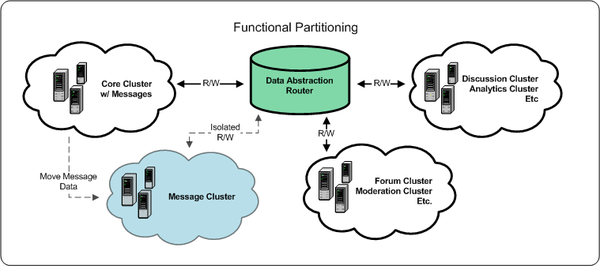
Through our analysis, we identified the following issues:
- Message data accounted for nearly 50% of the size of one database cluster
- Duplication of large data accounts for rapid, unnecessary growth
- Key index optimizations were missing
Based on this, we set the following goals:
- Isolate the message system into its own cluster
- Optimize the schema to reduce table locking
- Reduce the data size and duplication of data
- Accomplish the migration with little or no downtime
I’m pleased to report that after a long process of conversion, optimization and testing we have officially switched to the new backend for the message center. While this process proved to be quite tedious (and time consuming due to the initial size of the database – some alters took several hours to run!), the end result has been quite positive. Over the first few days we have seen both our overall database loads decrease, and the speed of the message center has increased. For those of you just wanting a high level overview:
We moved data around and changed it to increase performance and it worked. Thanks for reading, drive home safe!
For those wanting the nitty-gritty details, here you go:
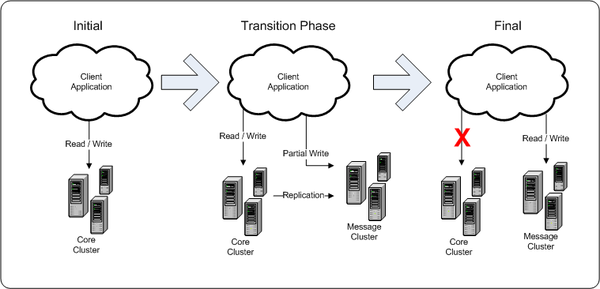
We started by dumping the schema only and all of the raw data in sql format as two separate dumps. From there, we restored the schema to another server and began to optimize the table structures. This was done through code analysis and heavy use of the “Explain Plan”. Once the initial alters were done, we loaded that schema combined with the original data onto empty MySQL 5.0 and 5.1 servers. At this point, we had the following rough statistics:
- Raw SQL: 87 GB
- Ibdata File: 134GB
We then fired up replication (using some table limiting and schema rewrite magic) and watched. After about a month of monitoring and analysis, we decided to go with MySQL 5.1 (with an ibdata file per table). This was chosen primarily because of the ability to split disk IO across multiple files. Side by side, the IO wait with a single ibdata file vs multiple files was quite evident. Once we landed on a server version, the data conversion began.
The main feature was removing duplicated message bodies while compressing them (i.e. if a user sends the same message twice, there is no need to store two copies of that message). So, we wrote a custom job that read the message body of every message record and stored/compressed a single copy while updating the table to only have the message hash. At first glance the savings here were amazing (although it took roughly a week to complete the job in its entirety). We then wrote and ran a few other custom jobs to populate some of the new fields we added during our analysis (these were mainly moved from table to table to eliminate joins – think speed here) and prune old data.
At this point, it was time to use the built in MySQL replication to our advantage. We updated our code to write to both the old and the new database for certain tables and stopped replicating those tables while we used replication to handle writes to other tables. This made our coding changes minimal. Once we had this in place, we ran alters on some tables to drop the now unused columns. Now, with our schema finalized, we starting replaying all the read traffic from our production databases against this new cluster. After making the decision that we were pleased with the performance, it was time to pull the trigger. We deployed our final code and severed replication from the original shared cluster, isolating all message traffic to an independent HA cluster.
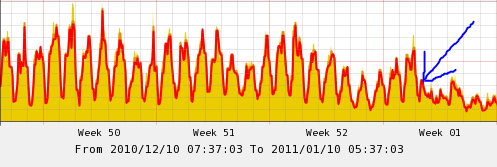
Here are our final stats after pruning and compressing along with a load graph showing the decrease in server load on our core cluster:
- Ibdata File(s) Total: 54GB (roughly 40% of the original size)
This undertaking was quite a challenge that taught us several lessons along the way, but was entirely worthwhile. Hopefully, as we continue to refine and optimize our application, this process can serve as a model for our future projects.